.avif)




This is Part 4 of a 5-part series on AI in UX Research. If you missed them, check out Part 1 for an overview of AI across the research workflow, Part 2 for planning and recruiting, and Part 3 for data collection and AI moderation.
In our series so far, we've used AI to help plan our research, recruit and schedule participants, and even moderate sessions. Now, we tackle what is often the most time-consuming part: making sense of it all.
Here's the thing about UX research: collecting data is often the easy part. It's what comes after that keeps us up at night. You've got twenty interview transcripts sitting in your tool of choice, each one packed with quotes, observations, contradictions, and tangents. You've got survey responses numbering in the hundreds. You've got usability test recordings where users struggled, succeeded, and everything in between. And all of it needs to become something coherent that your stakeholders can actually use.
This is the "messy middle" of research: analysis and synthesis. Without it, teams are stuck being data-rich and insight-poor. Historically, we’ve spent days (sometimes weeks 😅) manually coding transcripts, building affinity maps, hunting for patterns, and second-guessing whether we're cherry-picking the quotes that fit our narrative. The work is slow, manual, and prone to all the cognitive biases we're trained to avoid. This is where research velocity goes to die.
{{ibrahim-tannira-1="/about/components"}}
AI won’t soon replace a researcher's critical thinking, but there is something AI excels at here. It can't bring the business context, methodological rigor, or strategic instinct you've spent years developing, but it can tame complexity, accelerate sensemaking, and build a strong foundation for true synthesis, ultimately driving efficiency in your research process.
Before we dive in: Throughout this guide, we'll share various sample prompts. These are intentionally condensed to save space, but you can access the complete, detailed versions of these prompts along with instructions on how to use them by downloading our AI prompt library for research analysis and synthesis below.
Defining analysis vs. synthesis (& why it matters)
Before we dive into the "how," we need to get clear on the "what." We use "analysis" and "synthesis" together so often that they blur into a single concept. In order to get AI to help, we need to be rigorous about these definitions. The instructions you give for analysis and synthesis are fundamentally different. I like to think about it using the framework often cited in design thinking (and brilliantly articulated by folks like Jake McCann):
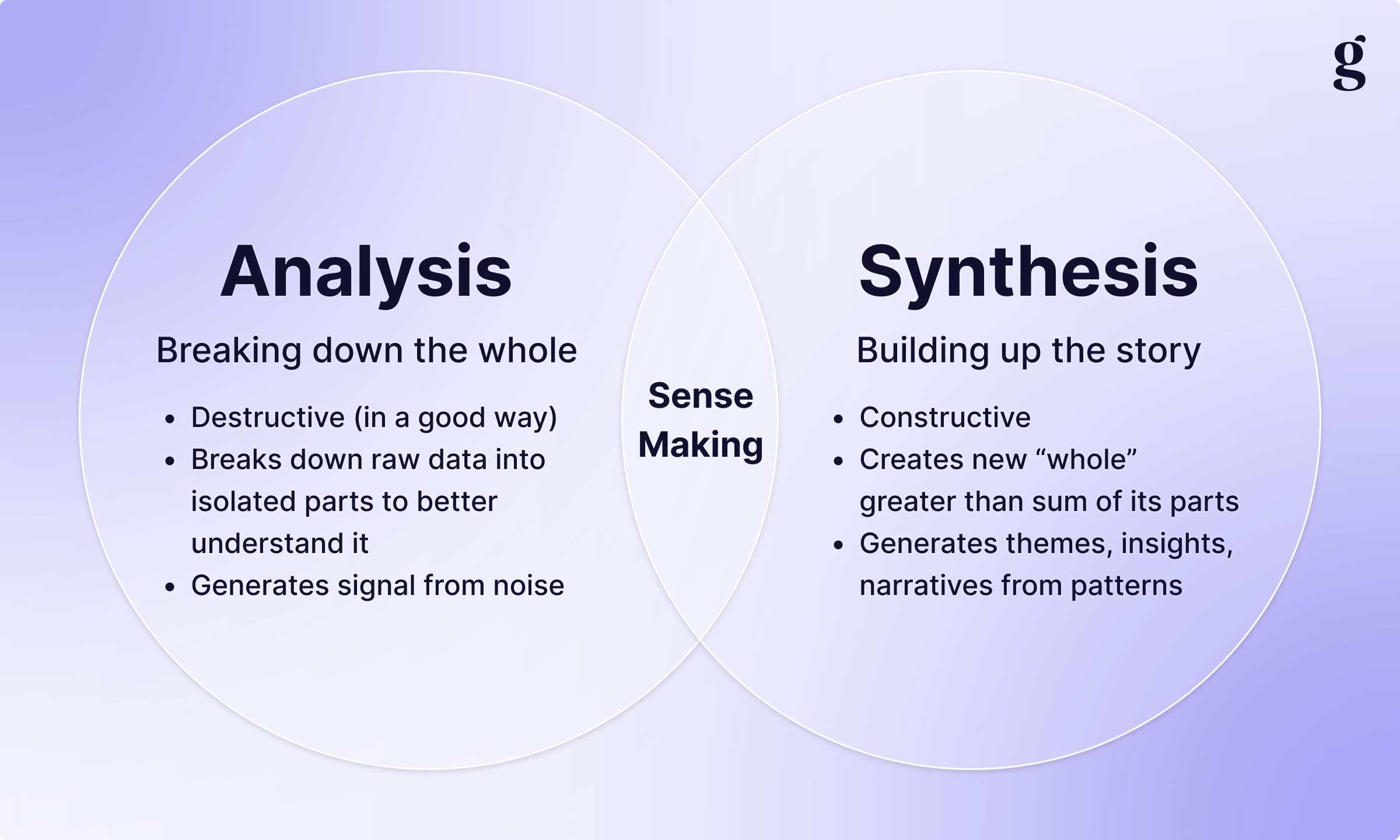
Analysis: Breaking it down (the "what")
Analysis is destructive in the best way possible. It’s the process of taking a "whole" (a single user interview, a survey response, a usability test) and breaking it down into its constituent parts in an attempt to identify what was said, what it means, and how it relates to our objectives. Without analysis, you simply have raw data, and usually an overwhelming volume of it at that. Analysis provides a per-session breakdown that helps us generate signal from noise.
Synthesis: Building it ip (the "so what")
Synthesis is constructive. It’s the process of taking those isolated parts you just broke down and combining them in new ways to create a "whole" that is greater than the sum of its parts. Synthesis generates themes, insights, and narratives by identifying patterns across sessions, transforming "what was said" into "what this means for our business." Without synthesis, everything stays siloed; you can't see the forest for the trees. Or, as I like to say: the plural of anecdote is not data.
Breaking down complex tasks into simpler ones that can be easily articulated is a core skill when working with AI. If you give an LLM a pile of transcripts and ask it to do analysis and synthesis, it’s unlikely you’ll get what you want back. Instead, by thinking through the inputs and outputs of each step in the process, we can get much cleaner and higher-quality outputs from our AI tools.
A context engineered workflow
If there's one thing that's become painfully obvious to me as I've worked with AI more, it’s that context management is absolutely crucial. You can't just throw twenty transcripts at an LLM and ask it to "do the analysis." Well, you can, but the results will…not be what you’re expecting.
Most people (and some products 😬) approach AI for analysis like this: dump all the data in, ask for themes, hope for magic. Sometimes it works; usually it doesn't. The context window gets overwhelmed, the AI loses track of important details, and you end up with generic summaries and hallucinated quotes.
What I've found works better is an iterative approach inspired by advanced context engineering techniques originally developed for coding agents. (Fair warning: that guide is written for software development, so it might be a bit technical for some, but the principles apply to any sufficiently complex task.) The key insight is this: break down each step into small, manageable chunks, and make sure each step produces a concrete artifact to use as input for the next step.
Instead of one massive "analyze everything" prompt, build a pipeline where each stage has a clear input, clear instructions, and a clear output. Think of it like an assembly line: each station has a specific job, and the product gets more complete as it moves down the line. We have to do this to work around AI's current limitations: context windows, hallucinations, inconsistency, etc. The workflow addresses these by never asking AI to do more than it can reliably handle in a single step.
Pro tip: Use Cursor, Claude Code, or any other tool that lets you see how much context window is in use. If it’s consistently over 60%, you need to break your task down even further.
The six-step pipeline
Here’s an overview of one way to break down analysis and synthesis into individual steps that an LLM can understand, along with some practical considerations at each step. If you want an even more detailed guide (including prompts), check out AI Analysis for UX from Senior UX Researcher Ibrahim Tannira.
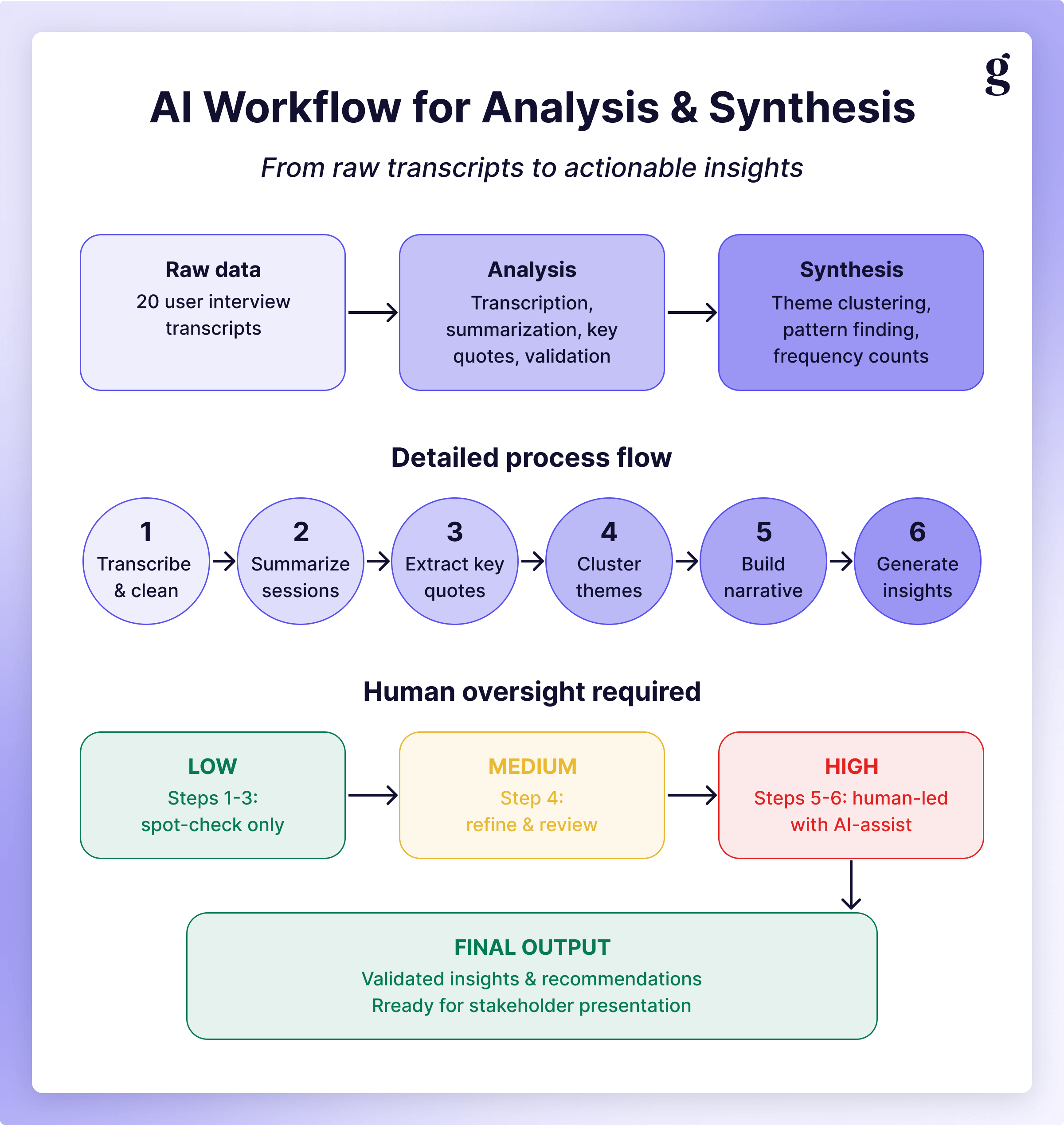
Step 1: Transcribe
I’m not going to spend a ton of time on transcription because it’s largely commoditized at this point. What’s important to note here is that you need to produce output that the next step/agent can leverage. For this reason, you’re probably going to want to use a spreadsheet. Make sure there are at least columns for timestamp, speaker, and the utterance (what was said) itself.
Why structure matters: When you have timestamps and speaker labels, you can programmatically separate facilitator questions from participant responses, filter by speaker, and later create highlight reels without manually scrubbing through hours of video. Structure also makes the transcript easier for AI to process.
Pro tip: Most tools can export transcripts in structured formats (e.g. CSV). If your tool only gives you text, simply ask an LLM to restructure it into a table.
Step 2: Summarize each utterance
Once you have the raw transcripts, you can stop worrying about the audio/video file until it’s time to make your highlight reel. Next, give the transcript spreadsheet to an LLM and ask it to add a "Summary" column where AI briefly summarizes what was said in each utterance. This is essentially open coding: turning raw speech into digestible concepts.
Prompt example: "For each participant utterance in this transcript, write a brief (~10 word) sentence summary capturing the key point, concern, or observation being expressed."
For example:
- Raw utterance: "Yeah, I mean, the whole process was just... I don't know, confusing? Like I clicked around for a while and couldn't figure out where to even start."
- Summary: "Expressed confusion about navigation and unclear entry point"
This transforms conversational speech (with all its ums, ahs, and tangents) into clean, codeable observations while staying close to the data.

Quality control tip: Spot-check the first dozen summaries. If they're too verbose, adjust the prompt to be more concise. If they're missing emotional content, ask for "expressions of frustration, confusion, or delight." Iterate until it's giving you what you need.
Step 3: Code the summaries
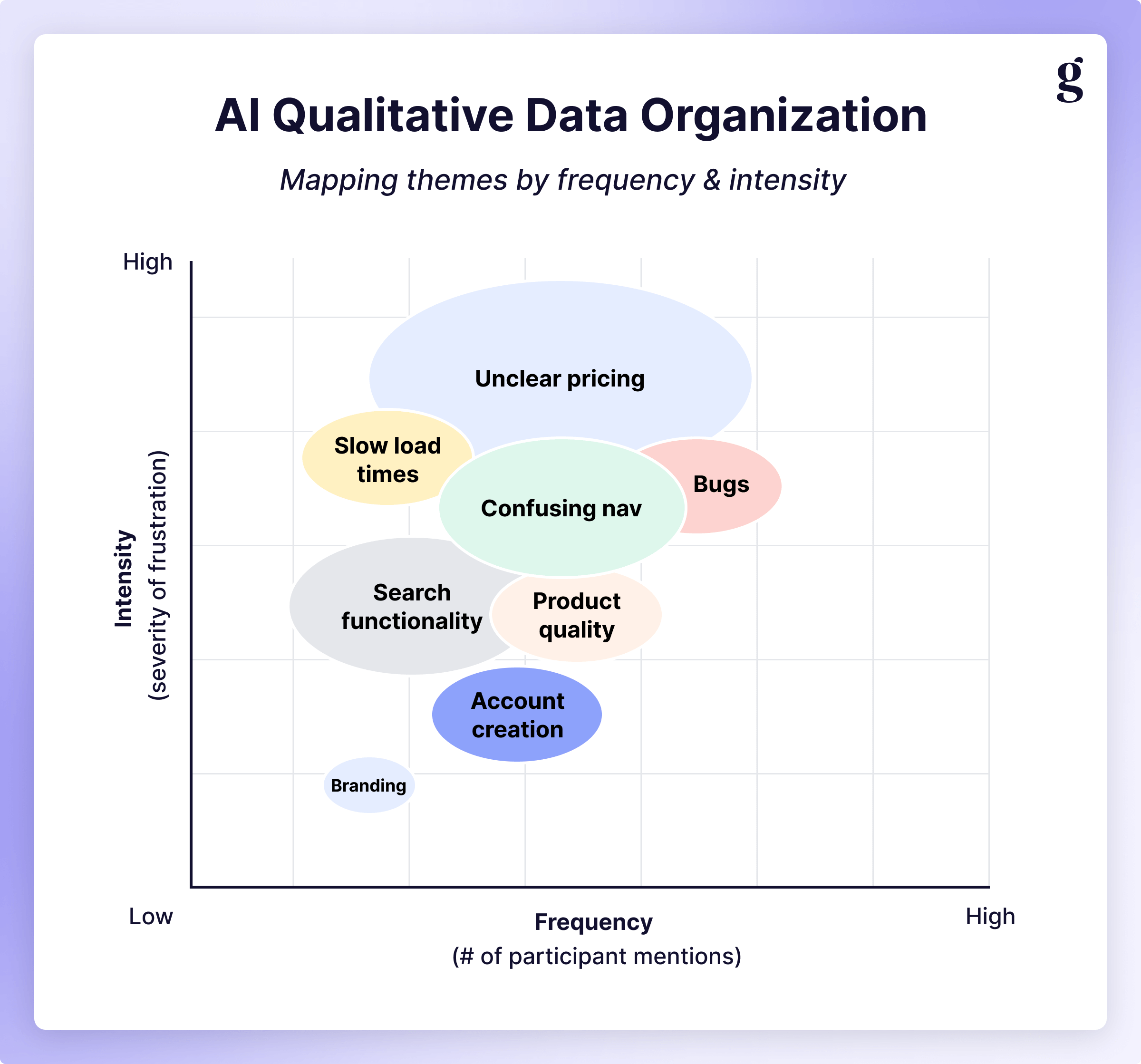
Using only the summaries produced in Step 2, create a small set of codes (10-15 total) that you'll use across your entire study. This is the shift from open to closed coding. Have the LLM add a "Codes" column and assign appropriate codes to each summary. This will be the basis of your synthesis. In the “old” way, this would be where you group your sticky notes together and give each group a label in your affinity diagram.
There are two ways to do this. If you know what you're looking for, feed that to the AI (e.g. "Use the following codes across all interviews: Navigation Issues, Pricing Concerns, Feature Requests, Performance Problems..."). If you don’t, simply ask the LLM to look at a few interviews and propose a code set.
Prompt example: "Review all the summaries across all interviews. Propose 10-12 codes that capture major themes. Each code should appear in at least 3 participants."
When humans do this step, we’ve already built an intuitive sense of the best codes because we’ve spent so much time with the material (in the sessions, transcribing, etc). You’ll have some of that if you were the one gathering the data, but don’t worry if not: if you don’t like the results, pick a different set of codes and have AI re-code. The structured workflow makes iteration easy because you can revise step 3 without redoing steps 1 and 2, and because we’re working with a limited scope (just the summaries), it should be fairly quick for an LLM to do.
Note: You may want to add additional steps before moving onto the synthesis half. Ibrahim adds another pass for sentiment (positive, neutral, negative); you could also add one for Frequency, Emotions, Feature/Props/Journeys, etc. See Tomer Sharon’s foundational post about insights nuggets for more.
Step 4: Identify patterns
With everything coded, we can move from breaking things down to putting them back together to start our synthesis step. Feed all of the coded transcripts into your LLM and tell it only to attend to the Codes column, with the goal of identifying patterns across sessions. This is where you start to get curious and ask questions of your data, and what it produces will serve as the basis for the narrative you’ll ultimately build to share with your colleagues.
Prompt examples:
- "Which codes appeared most frequently? Provide counts."
- "Which codes often appeared together? What might that tell us?"
- "Are there differences in code frequency across user segments?"
Because you've structured and coded your data, AI can now give you reliable pattern analysis. With unstructured transcripts, asking AI to search through them all will quickly overwhelm the context window, quickly leading to AI slop. Instead of searching for a needle in a haystack, the AI is just counting and correlating structured data (which is something it’s really good at).
This is a good opportunity to get curious and playful with your data, as well. When doing this manually, you’ll start to notice patterns and connections intuitively after spending hours upon hours with the raw data. We still need to make sense of what’s there, though, so don’t feel bad if you spend an hour asking questions here: you’ve likely already saved 20+ hours of time by not having to watch and re-watch every session to transcribe, annotate, and code your findings.
Step 5: Craft your narrative
Once you have a good sense of the data, we can move beyond simple frequency counts. Stakeholders don't want to hear "17 people mentioned pricing"; they want to understand the story of why pricing matters, what it reveals about user priorities, and how it connects to their decision-making process. AI can help you move from data to narrative, and can even help you stress-test different stories for different stakeholders/perspectives.
Prompt example: "Given these themes [Pricing Concerns - 15/20 participants, Comparison Shopping Behavior - 12/20 participants, Trust Issues - 8/20 participants] and their relationships, draft a narrative that walks our [Head of Customer Success, CMO, PM for this feature] from the user's initial problem through their decision-making process. Include the emotional journey and key decision factors."
What you'll get is a complete narrative (beginning, middle, and end) that connects your findings into a coherent story, customized for the perspective you’re appealing to. It won't be perfect (transitions might feel clunky, emphasis might be off, etc.), but instead of staring at a blank page you have something you can react to or iterate on.
Why this matters: Stakeholders remember stories, not statistics. When you frame your findings as "Users start confident about switching, but pricing uncertainty creates anxiety that drives them to competitors" instead of listing three separate themes, you're giving them something they can act on. AI may generate the words and overall structure, but you need to bring the business context. You know what priorities are and what different stakeholders care about.
Step 6: Extract representative quotes
Once you’ve hammered out your key narratives and talking points, you can leverage AI to extract direct quotes to add some emotional punch. Instead of scrubbing through hours of video, leverage the spreadsheet to find the exact quotes related to the themes you’ve selected.
Prompt example: "For 'Navigation Issues,' find 3 quotes that best represent this theme. Include participant ID and timestamp. Quotes should be concise, clear, and representative, and direct."
Traceability is crucial, which is why way back in Step 1 we included timestamps in the transcript. Being able to identify the precise moment across multiple interviews where participants said similar things helps illustrate that this is a pattern, not just one or two passionate people, and being able to use their own words instead of “users find pricing confusing” adds emotional resonance with your audience. Bonus points for video and audio highlight reels, which add tone and facial expression to the words.
Why this workflow works
The magic isn't any individual step; it's that each step produces a concrete deliverable that enables the next. Your transcript becomes a structured spreadsheet, your spreadsheet gains summary columns, your summaries become codes, and so on, all without overwhelming AI's context window. Each stage operates on manageable chunks with clear instructions, tracing each insight back through the layers: insight → theme → coded summary → original utterance → timestamp. (No need to ask yourself: "how did I get here?")
If something looks wrong in step 4, you can revise step 3 without starting over completely because each artifact is both reusable and independent. In fact, once you build this pipeline, you can reuse it. Your code set might evolve study-to-study, but the structure and process stay the same: AI handles tedious parts (transcription, summarizing, counting) while you focus on judgment calls (selecting codes, validating patterns, building a narrative).
Practical considerations
Choose the right tool
As you get more comfortable with the process, play around with different tools for each step. Even for something as “simple” as transcription, outputs can vary widely. This is especially true when dealing with accents, languages other than English, or domain-specific terminology. All of your favorite research tools may have transcription built in, but you also might want to experiment with dedicated tools like Otter, Fathom, or Descript. Starting with a good transcript is crucial for the rest of the process. As with most things in the domain of AI: garbage in, garbage out. AI synthesis works best when your data lives in a centralized research repository - not scattered across Google Docs and Slack threads either.
In addition to AI-moderated interviews, Great Question also has AI analysis and synthesis. After every interview, Great Question uses the transcript to automatically generate:
- Summaries of key takeaways and themes
- Chapters for easy transcript and video navigation
- Highlights based on your research study goal
- Tags to help you organize all of your insights and artifacts
{{olivier-thereaux-1="/about/components"}}
You can also query entire studies with up to 50 hours of interview data in seconds: ask for specific quotes, insights, answers to questions, or a custom summary or report.
Most importantly, it's all traceable and secure:
- Every quote is linked to its original transcript, so you can jump to the exact moment it occurred and verify accuracy.
- Great Question masks PII from AI, so data will never be used by 3rd parties for training future models.
{{raz-schwartz-1="/about/components"}}
Start small & iterate
Rome wasn’t built in a day. Don't implement the full workflow on your most important study right away. Start with a few interviews on a project you have some extra wiggle room on and work through the process. You'll discover where prompts need refinement, where AI gets confused, and which models work best in different situations.

An eye for diversity
When analyzing studies with diverse participants, be very mindful of how AI handles different populations and perspectives. There are two things to watch for here:
- Due to their training data, LLMs may over-emphasize dominant voices while downplaying marginalized perspectives,
- Because LLMs produce summaries that tend to smooth over outliers, unique perspectives may get lost in the shuffle.
One way to get around this is to explicitly prompt AI to look for divergent viewpoints: "What themes appear in fewer than 3 participants but might still be significant?" or "Are there patterns unique to [specific user segment]?" If you plan to use AI to generate summaries, I’d encourage you to reserve a space in your output for this.
Build your prompt library & meta-prompt
It’ll take you some time to get to something that works reliably: don’t worry, that’s totally normal. One thing you can do as you iterate through solutions is use what’s called “meta-prompting”: asking the LLM to improve the prompt you gave (or write a new one if you’ve been chatting). Every time you go through one step in the process, you can improve the prompt for next time. Once you get to something that you’re happy with, save it (or, better yet, create a Gem or Custom GPT so others can use it). You will eventually wind up with your own prompts for summarization, coding, pattern finding, diversity analysis, quote extraction, redaction, etc.
Don't reinvent the wheel every time. Build reusable assets to increase efficiency.
Advanced capabilities
Once you’re feeling comfortable with the above workflow, there are a variety of ways AI can improve your analysis & synthesis. Here are a few ideas to get you started.
Auto-redaction
Starting as early as the transcript, you can train your AI assistant to recognize sensitive information and redact it from the transcript, alleviating any downstream concerns about participant privacy. In its simplest form, LLMs can simply add a “[redacted]” into the transcript, but if you want to get fancy with it (and acknowledge the slight risk of misrepresentation), your LLM can insert something into the transcript that flows smoothly without changing the meaning (i.e. swapping out proper nouns).
If you have stakeholders that get suspicious when they see something redacted, experiment with this technique to protect PII without anyone even knowing. 🥷
Bias check
One of the most underutilized applications of AI in analysis is using it to validate (or invalidate) your hypotheses on a per-session basis. Before you conduct research, you presumably had some expectations about what you might find; AI can help you systematically check those expectations against what actually happened.
Try something like this:
Prompt: "Based on the attached research plan, what from this interview validated our initial assumptions? What contradicted them? What emerged as a new theme we didn't anticipate?"
This helps you confront your biases early, which can pay huge dividends long-term. If you assumed users would struggle with feature X but the transcript shows they barely mentioned it, that's valuable information. Conversely, if they spent ten minutes unprompted talking about a pain point you hadn't even considered, AI can flag that for deeper investigation. I’ve never run a study that doesn’t include some additional nuggets that are out of scope of the initial investigation.
The key here is using AI as a reality check. You bring the hypotheses; AI brings the systematic cross-referencing. Together, you get a more balanced picture than either could produce alone.
Auto-generated highlight reels
Picture this: you just finished your twentieth interview. You know that somewhere in those hours of video there's a perfect quote that encapsulates the core user frustration. But where? Scrubbing through recordings is mind-numbing work, and by session fifteen, they all start to blur together. This is another area where AI shines. Instead of manually hunting, ask it to surface the moments that matter:
Prompt: "Extract the 3 most powerful, concise quotes that illustrate this participant's frustration with the login process. Include timestamps."
It’s possible to return not only the quote but a direct link to that moment in the recording, allowing you both to verify the transcript & context within seconds but also to pull that segment for a highlight reel, automatically generating highlight reels for your most impactful moments
Want to go deeper? Ask for quotes that represent different sentiments, that exemplify differences in customer segments, or request examples that show evolution in the participant's thinking over the course of the session. AI is particularly good at finding linguistic markers of emotion such as confusion (e.g. "wait, how do I..."), delight (e.g. "oh, that's neat"), or frustration (e.g. "ugh, this is ridiculous!").
Looking ahead
Leveraging AI in this way can make you more efficient, but as always, there is room for improvement. The process is still fairly manual, so consider looking into automations via Make, Zapier, or n8n. Imagine synthesis that happens in real-time during data collection, flagging emerging themes after 3-5 sessions in case you want to tweak your methodology. Taking it a step further, we could have an AI assistant automagically aggregate findings from previous research to create longitudinal insights, or you could have an AI assistant integrated with your other tools, allowing it to suggest which findings are most actionable based on your product roadmap.
We're not there yet, but we're probably not as far off as you think.
For now, the opportunity is clear: AI can transform analysis and synthesis from a manual slog into a faster, more dynamic partnership.
Researchers who build structured workflows and understand context management won't just save time, they'll produce better research and reclaim bandwidth for strategic work AI can't touch.
The bottom line
The "messy middle" of research will always be messy: that's the nature of working with human complexity. What AI offers is a way to navigate that complexity faster and more systematically (through structured workflows and context management) so you can focus on the things that truly matter.
The six-step pipeline isn't the only way to do this work, but it follows the important principles: each step produces an artifact, each artifact enables the next step, and you maintain visibility and control throughout. You're structuring your work around AI’s current limitations to ensure it produces something useful.
Now that we've used AI to find our insights, how do we stop them from being forgotten? In our final guide, we'll explore how AI moves knowledge management into insights activation, ensuring that all this hard work actually has an impact.
Have you experimented with AI for analysis or synthesis? What's working for you? What challenges have you hit? I'd love to hear about it. Reach out on LinkedIn or email me with your experiences.
Related resources:
- Download: Prompt Library for AI Analysis & Synthesis (featured here in this guide)
- Download: AI Research Story Generator (featured in Part 3)
- Download: AI Research Planning Assistant Template (featured in Part 2)
- Download: AI x UXR Tool Comparison Guide (featured in Part 1)
- Sign up to get notified when new AI guides & resources go live