.avif)




Welcome to the fifth and final guide in our series on AI in UX Research. If you missed them, check out Part 1 for an overview of AI across the research workflow, Part 2 for planning and recruiting, Part 3 for data collection and AI moderation, and Part 4 for analysis and synthesis.
Picture this: you've just wrapped up a fascinating study. The findings are crisp, the recommendations are clear, and you're confident this research will change how your team thinks about the problem. You write a beautiful report, upload it to your research repository, send the deck to stakeholders, and... nothing. A few months later, someone asks a question that your study already answered. Nobody checked the repository, and anyone who read the report didn’t internalize it.
I’m sure that’s never happened, right? 🙃
This phenomenon is called "research amnesia", the organizational forgetting that happens when insights get filed away instead of staying alive in product conversations. In our final guide of this five-part series, we're tackling the last mile: ensuring the hard-won insights from your planning, recruiting, moderation, and analysis actually drive decisions and shape what gets built.
Going deeper: If you want a more systematic framework for thinking about AI agents in knowledge management, check out Jake Burghardt's excellent piece on AI Agent Ideas in Research Knowledge Management. He breaks down five specialized agent types and their use cases—great companion reading to this post.
The knowledge management trap
There's a core problem with traditional research repositories: they're either easy to put data in or easy to get data out, but it’s almost impossible to do both. Want to make it easy to contribute? You end up with a messy pile of untagged transcripts, inconsistent formats, and zero findability. Fine, let’s make it easy to search then. Now we’re burdening researchers with complex metadata schemes, strict taxonomies, and time-consuming uploads that nobody has bandwidth for. Pick your poison. ☠️
“Bad Research Memory” was one of the core problems Tomer Sharon (and team) set out to solve with their Polaris system back in 2016, and while repos can help, the problem still plagues us today. Teams build elaborate repositories that ultimately become digital graveyards full of valuable insights that never see the light of day. Everything is there—reports, insights, tags, recordings—but they might as well not be because nobody's checking.
We've all heard the mantras: "Make research findable!" "Build a single source of truth!" "Create a research repository!" These aren't necessarily wrong, but I’d argue they’re incomplete. A perfectly organized taxonomy doesn't put insights in front of stakeholders when they're actually making decisions. Findability alone doesn’t impact decisions.
What we need isn't better knowledge management, but activation. And AI can help.
From management to activation: A paradigm shift
Traditional knowledge management operates on a "pull" model. In most companies, PMs and Designers simply DM their Research partner asking a question (or post in a general #ask-research channel), and someone from the Research team goes excavating the repo, creating a complex query that they can send back to their stakeholder. If you’ve provided DIY enablement, this requires the PM/Designer/etc. to (hopefully) remember that the repository exists, navigate to it, search for relevant keywords, filter by date or topic, comb through piles of results, and maybe, eventually, find what they need. That's a ton of friction, and somewhere along the line people either lose the plot or give up.
{{thomas-stokes-knowledge-management="/about/components"}}
AI is helping us break this model in two fundamental ways: improving the pull experience and enabling an entirely new push model.
- The new pull model means stakeholders can ask natural language questions instead of guessing keywords. "What are the biggest pain points we know about in the checkout flow for mobile users?" beats trying to remember if you tagged that study with "checkout," "payment," "mobile," or "e-commerce." The system understands intent, not just exact matches. It can synthesize across multiple studies or surface adjacent findings you didn't think to look for.
- The push model is even more interesting. Instead of waiting for people to come looking, insights can flow proactively to where decisions happen. A weekly digest highlights fresh findings for teams actively working in those problem spaces. A bot in Slack notices someone planning a feature redesign and surfaces relevant past research. A JIRA ticket gets auto-populated with customer pain points before engineering even starts building.
Go to where the people are: instead of demanding someone break their train of thought or way of working to seek insights, bring insights right into the context where people are working. This was always possible, but now AI gives us the infrastructure to do it at scale.
The new pull: Chat with your data
Let's start with improving how people find research when they go looking for it. Semantic search is the obvious first step, and it's genuinely useful. The difference between searching for keywords and asking questions in natural language is night and day, especially for DIYers who are interacting with your taxonomy infrequently.
- Old way: Keyword: "checkout" AND tag: "Q3-2025" AND methodology: "usability testing"
- New way: "What do we know about why users abandon checkout on mobile?"
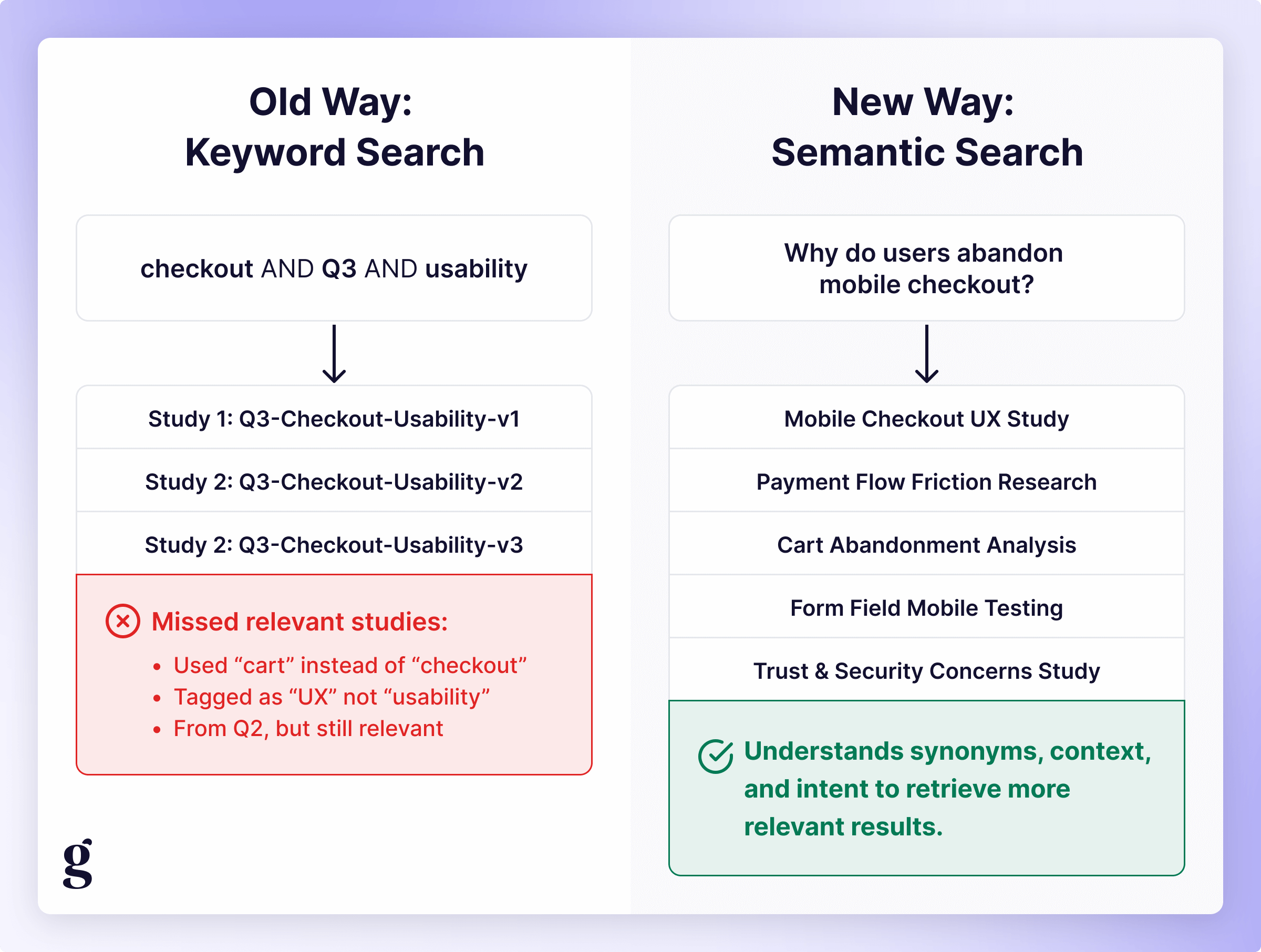
The system can understand synonyms (“cart” vs. “basket” vs. “checkout”), related concepts (“mobile” vs. “responsive” vs. “small screens”), and even infer intent (“abandonment” might pull in findings about payment friction, trust issues, or form usability), dramatically decreasing friction and lowering the barrier to finding relevant insights.
Here's where it gets more interesting: AI-suggested taxonomies and auto-tagging can help solve the "easy to put data in" side of the equation as well. If you don’t have a taxonomy at all, you can enlist an LLM to help you start building one out or periodically revising your taxonomy as new data rolls in. If you haven’t reviewed your taxonomy in over a year, you should. 😉
Once you have a taxonomy in place, your AI assistant can automatically suggest tags when you upload any new content (e.g. product area, user segment, pain points). One of the biggest challenges in keeping a repository both clean and up to date is the ingest process. If AI can reduce that burden by even 50% (if not 80% or 90%), suddenly it becomes much easier for anyone to contribute while keeping the repo clean. No more gatekeeping who can add to the repo, reducing the burden on your ResearchOps function.
However, there are also risks. AI auto-tagging is highly prone to overconfidence, happily generating tags that seem plausible but miss crucial context or misinterpret nuance (especially when it comes to things like tone of voice, sarcasm, body language, or facial expressions, which most AI systems cannot properly interpret…yet). This is why keeping a human in the loop (HITL) is crucial.
Friendly reminder: AI solutions are assistants, not replacements. The goal is to make humans more efficient and free us up to do more important and interesting work.
AI-empowered meta-analysis
If you have a well-structured and cleanly documented taxonomy, you can do something else interesting with a standard LLM. If you recall our discussion about context engineering in Part 4, it’s crucial to limit how much you’re asking an LLM to ingest and work on. You can’t give it your entire insights repo, but if you tell it just to read the executive summaries from a set of studies, you can pull out trends across multiple research studies.
Here are a few prompts to try:
- "Review all research from the past 12 months. What themes or contradictions emerge that we might have missed in individual studies?"
- "Which customer problems have been mentioned across the most studies but still haven't been addressed in our product roadmap (attached)?"
- "What insights from 2024 are potentially outdated given what we learned in early 2025?"
This kind of meta-analysis is both incredibly valuable and incredibly time-consuming to do manually, often requiring deep institutional knowledge to even know which studies exist in the first place. AI can surface patterns across dozens of studies that no individual researcher would have the bandwidth or context to connect.
Just remember to trust, but verify: make sure you tell it to cite which studies support its claims, and if it pulls any quotes, provide a specific study/participant/timestamp. Don't take its word as gospel.
AI can also work proactively with documents people are already creating—what Jake Burghardt calls a "Research Alignment Agent" that analyzes PRDs or design briefs and suggests relevant research without anyone needing to search.
The new push: Insights in the wild
Making it easier to pull insights is powerful, but proactively pushing insights out is transformative. This is where we move from making a repository better to fundamentally changing how insights flow through an organization. None of this is impossible without AI, but using AI certainly makes it more practical and scalable.
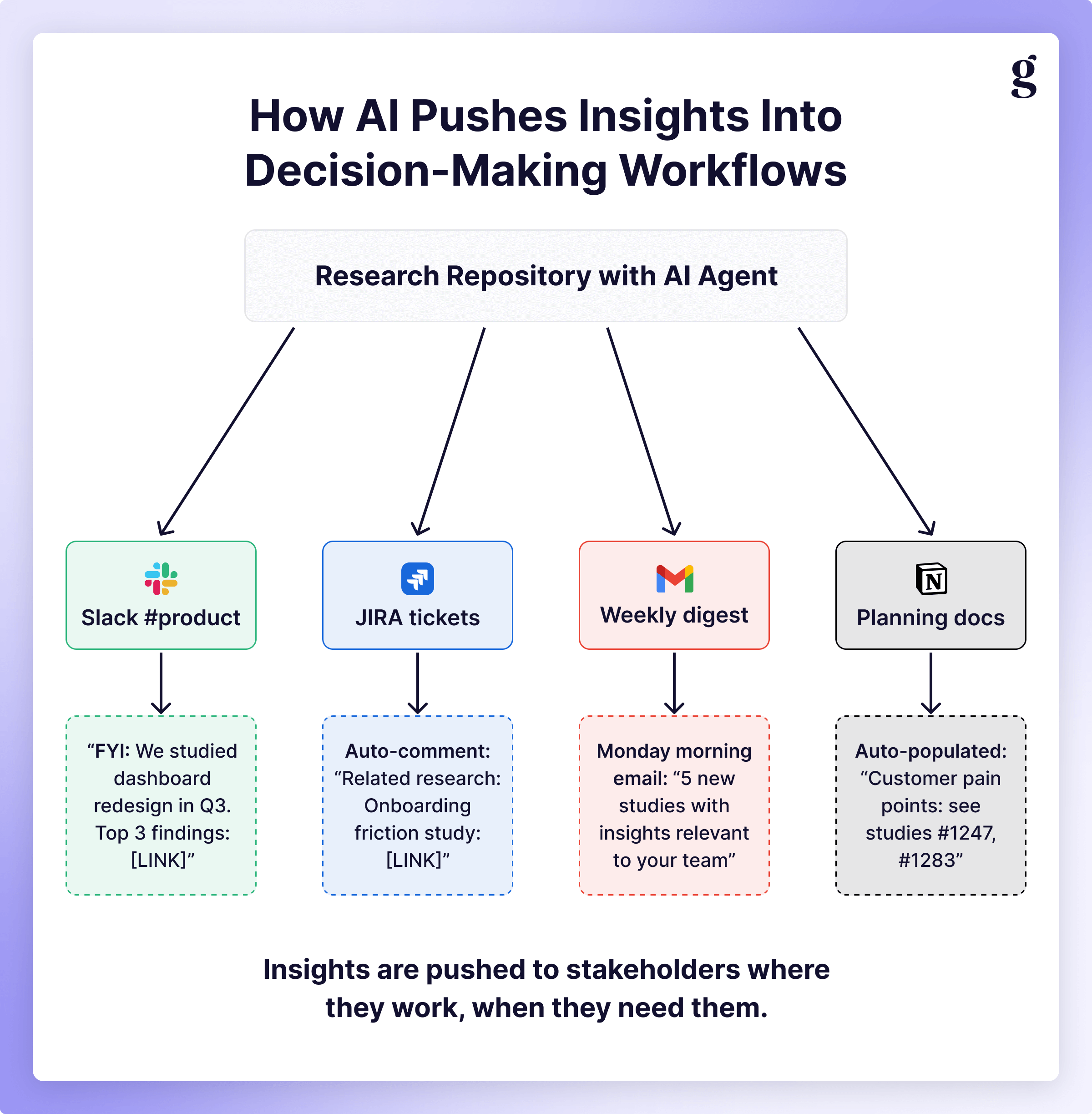
Slackbot research assistant
Imagine a bot monitoring key channels (e.g. #product, #design, #roadmap-planning, etc), watching for trigger phrases (tailored to your organization) that indicate people are asking questions or making decisions that research could inform:
- A designer posts: "We're thinking of redesigning the dashboard layout next quarter."
- The bot notices and replies: "FYI, we did a usability study on dashboard layouts in Q3 2024 [link]. Here are the top 3 findings: (1)... Want me to summarize the key recommendations or provide direct quotes from participants?"
This brings research to the conversation exactly when it's relevant without requiring anyone to remember or go searching. The key is tuning the bot's sensitivity: you want it to surface truly relevant research without becoming noisy spam that people learn to ignore or completely shut off.
AI-enabled share-outs
If you don’t already have one, I highly recommend building some sort of regular cadence around sharing insights (on top of the above ad hoc responses). Auth0 had a variety of ways to regularly push insights out to the company (including an “Insight of the Week” bot and a monthly Research Roundup). While those practices are great, they fail in two ways that AI can help: they’re generic and time-consuming. By leveraging AI, we can:
- Identify which studies have finished recently.
- Extract the most relevant findings for different audiences (e.g. Exec, PM, Marketing, Customer Success, Sales, specific product/feature team verticals).
- Draft customized summaries for each team.
- Include links back to full reports for those who want to dig deeper.
This not only saves your ResearchOps team time (usually spent chasing down whoever did the Research to put a few slides or bullet points together 😅), it produces output that would otherwise be impractical (building out different summaries for each audience). What used to take hours of time every month can be almost completely automated: all you need to do is review the summary to ensure it’s accurate before it gets posted to the relevant channels.
Research copilot
Having something monitor Slack and push content out is cool, but the real unlock happens when you integrate with project management tools. Imagine a JIRA ticket is created for "Redesigning the onboarding flow." An AI agent can:
- Scan your research repository for relevant past studies.
- Surface the top 3-5 most important findings about onboarding.
- Automatically add a comment to the ticket with those insights and links.
- Tag the research owner in case the PM or designer has questions.
This is the exact opposite of how insights repos work at most companies. Instead of research findings being buried in a database somewhere, it's right there in the planning artifact where discussion is happening and decisions are being made. It’s not just available; it’s unavoidable.
You can even build systems that work in reverse—monitoring where research gets cited in planning tools and pulling that impact data back into your repository to track ROI.
Building a smart repository: Ethics & best practices
Before you start dreaming about an AI-powered insight utopia, let's talk about the risks and requirements. AI won’t magically fix a broken system; if anything it amplifies what you've already built. If your current repository is a chaotic mess of unorganized Google Docs and random Zoom recordings, AI is likely going to create more WorkSlop (and hangover) than benefit.
Rule: Garbage in, garbage out
AI can only surface what you've structured well. This means committing to an atomic, nugget-based approach to organizing insights if you haven’t already. Think of it like this: instead of just uploading full study reports, you break findings down into discrete, tagged insight summaries. Each "nugget" is a single insight with:
- A clear statement of what you learned
- Evidence (quotes, clips, data points)
- Metadata (tags, dates, participants, methodology)
- Links back to the full context
Tools like Great Question, Dovetail, and others are built around this concept. The atomic structure is what makes AI excel: the system can surface specific, relevant insights rather than dumping entire 40-page reports on someone's desk.
Don’t have your research atomized? Don’t fret—follow the steps in Part 4: Analysis & Synthesis to have an LLM help. 🤖
Risk: PII & Privacy
This is the #1 ethics concern with AI-powered knowledge management. Your repository contains raw participant data: recordings, transcripts, personally identifiable information, etc. Whatever AI tools you use must have enterprise-grade security settings at a minimum (and, ideally, automatic PII detection and masking). Do not upload participant data to consumer AI tools like ChatGPT's free tier or Claude's standard interface. This is non-negotiable.
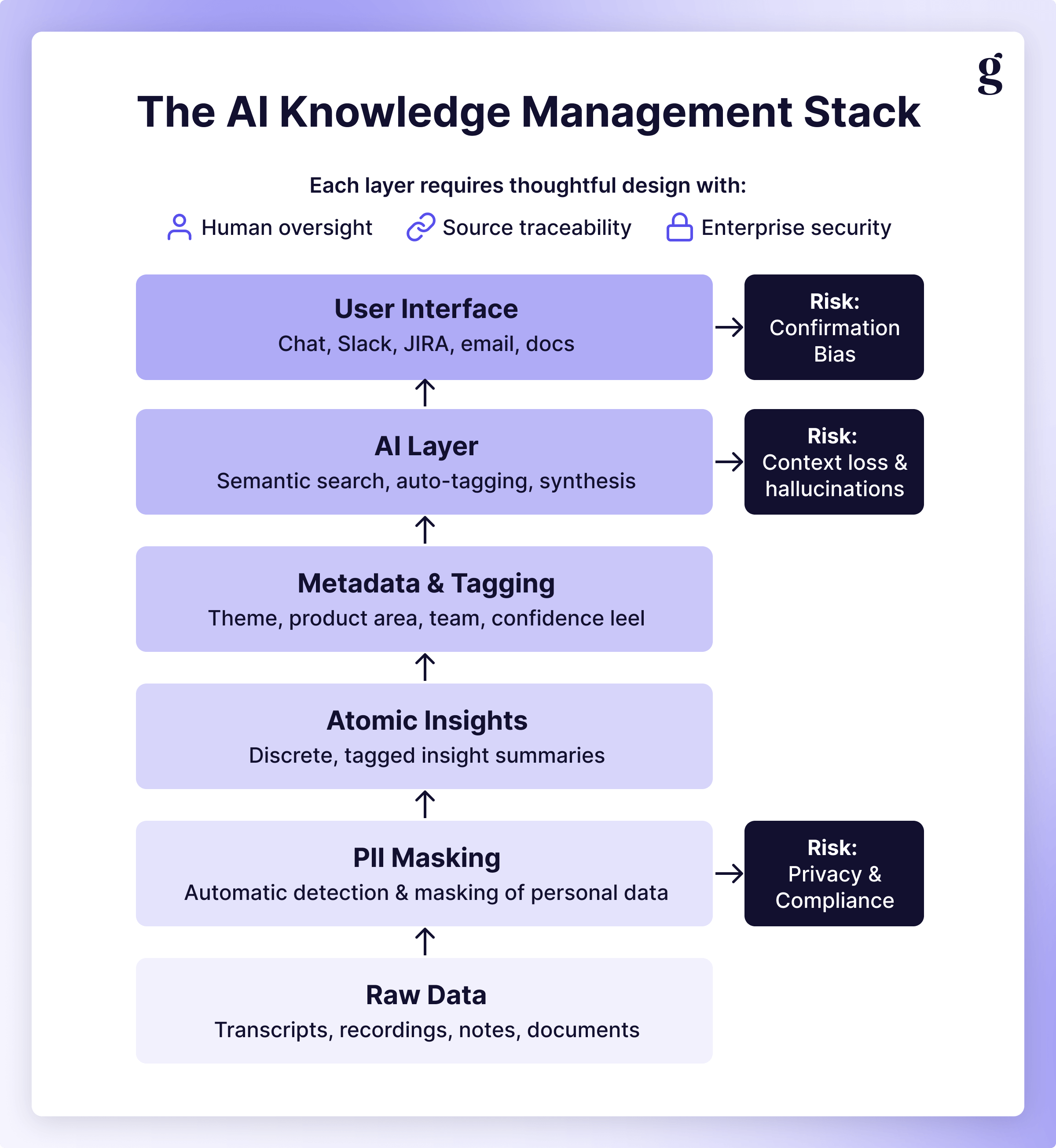
Risk: Loss of context
I can't stress this enough: Context is king. Your AI assistant might surface a quote that sounds powerful in isolation but the original context completely changes its meaning. The LLM might pick up on “Y’know, [feature] is great and it saves me a lot of time…” without recognizing there’s a “...but it’s just too [expensive/cumbersome/risky] for us to use regularly” coming after a healthy pause or a prompt from the facilitator. It could also surface a quote from a concept test or previous design that is no longer relevant without proper guardrails.
Maintaining context is difficult, and should be part of your nuggetization process. Every quote, note, finding, or recommendation should include a direct link to the reports, studies, and participants being referenced. The human-in-the-loop (HITL) step needs to make it easy to verify any claims that seem too good to be true.
Risk: Confirmation bias & leading questions
Most LLMs have a positivity bias, erring on the side of providing any sort of answer instead of pushing back or simply saying they don't know. If a PM asks it to find evidence that users love a certain feature, it will find something; even if that requires cherry-picking the one positive comment from a study that was overwhelmingly negative.
To help avoid confirmation bias with an AI veneer, we need to ensure our assistants know how and when to push back and provide appropriate context. This can take many forms:
- "I notice your query assumes users love this feature. Would you like me to show you all feedback, including critical perspectives?"
- "There are 3 quotes supporting this hypothesis and 7 that contradict it. Maybe we should investigate why?"
- "I found extremely limited evidence on this topic. Let’s consider running a new study."
- "Here are the top 3 favorite things and top 3 pain points about [feature]:"
You’ll need to experiment with which style (or “personality”) works best for your culture. There’s a time to be optimistic and highlight wins and opportunities and a time to be skeptical and surface risks. Presenting multiple perspectives helps avoid your AI becoming another echo chamber of false positivity and can help identify critical gaps in your organization’s knowledge. 🔮
Beyond these three risks, there's also the question of ongoing maintenance. Repositories need "gardening"—checking governance compliance, validating metadata as your taxonomy evolves, archiving outdated insights. Most teams never get to this because researchers are busy with new studies. AI can systematize repository maintenance tasks that would otherwise never happen.
What this means for research operations
If you're in ResearchOps, this shift is particularly significant. Much of traditional ReOps work has been about building and maintaining infrastructure: setting up repositories, creating templates, managing taxonomies, organizing files. We’ve always had automations, but AI is making it much easier to build systems to handle the majority of the mechanical work. What this means is you need to focus on the things AI can’t currently do:
- Define what quality looks like for your organization
- Decide which decision moments matter most
- Understand how your colleagues make decisions
- Design the flows that push insights to stakeholders
- Coach teams through adoption friction
- Set the standards for what counts as an insight vs. an observation
- Build the rituals that make citing research feel normal instead of effortful
The practice is evolving from "repository manager" to "insights system designer." You're not just maintaining a database anymore: you're architecting how knowledge flows through your organization. That's harder work the requires you to understand how other teams operate and make decisions but it's also more strategic and more valuable. AI is laying bare something that’s always been true: it’s simply not good enough to build a giant repository. You need to understand how to create change within your organization in order to be successful. AI is just another tool in your toolkit.
Related read: Change management for UX research teams by Johanna Jagow
Getting started: Three moves to activate your insights
This may seem daunting, but Rome wasn’t built in a day. Here are three tactical moves that compound over time to shift from passive knowledge management to insights activation and prepare your research function for AI enablement.
1. Simplify your taxonomy
Since 2018, insights repositories have become commonplace for most research teams. Over that same time span, as the amount of data we capture has grown, so has the desire to categorize everything, blowing up taxonomy sizes into the hundreds (or even thousands 😳). LLMs already have the ability to search for arbitrary text (e.g. read all executive summaries), but they perform worse without structure, and if your taxonomy has 1000+ tags, that’s just as unstructured as the raw text itself.
Challenge yourself to get down to just a few categories (e.g. Product/Feature Area, User Journey, User Type) and limit the number of options within each category. If you’re struggling with this, ask your friendly AI assistant for help. Try both of these approaches for inspiration:
- Give it your existing taxonomy and ask it to simplify.
- Give it a set of executive summaries and ask it to create a new tagging system.
This minimal taxonomy is optimized for routing insights to action, not for perfect categorization. The goal is getting the right insights to the right teams, not academic precision.
2. Focus on a few (two?) forums
Instead of trying to build something that works for everyone everywhere all at once, pick a small set of existing practices you want to inject insights into. This could be a weekly ritual (product sync, design critique), a specific channel (e.g. #product-org, #roadmap-discussion, #customer-feedback, #ask-uxr), or larger-format meetings (monthly/quarterly all-hands, or roadmap planning). I would advise starting small and building up.
For each forum, a few key things to identify/decide:
- What are the triggers for your assistant to activate? e.g. keywords, regular cadences, explicit activations (DM to the bot, button, query, etc)
- Who do we want to target? PMs? Designers? Researchers? Marketing?
- What do we want to present and how? Slack post? Confluence doc? Highlight reel? Summary? Link to the study?
Build the simplest thing possible (even if it means you spend a few hours sitting in a channel and manually generating these reports) and see how people react. I recently asked ChatGPT to summarize the past two weeks of any channel with “feedback” in the name as part of building out a Voice of the Customer program and people were very impressed with what was ultimately a very simple query.
3. Build durable insight pages
In the old model, each study was a discrete event: you ran research, shared findings, made recommendations, and moved on. Six months later when someone encounters a related problem, they might not even know your study exists, starting from zero again.
Instead, structure your repo not around individual studies but around key themes and insights. Once you start hearing about onboarding friction, start an insight page. Whenever we learn something new (from any study), those findings show up here. Over time you build a robust, multi-study synthesis that carries real weight. When someone starts planning an onboarding redesign, the system automatically surfaces this accumulated knowledge. Insights don’t decay over time—they grow stronger.

This creates a domino effect across the entire organization:
- Insights become institutional knowledge instead of one-off studies.
- New hires can get up to speed faster.
- Product leaders can make decisions with confidence that they're building on everything we know, not just the most recent study.
- Teams avoid rediscovering the same problems over and over.
AI is the infrastructure that makes this possible at scale. It handles the mechanical work of connecting related insights, surfacing relevant research at decision points, and maintaining the knowledge graph as it grows. But humans still define what matters, curate quality, and design the flows that ensure insights shape decisions.
Wrapping up our AI for UXR series
We've now covered every major step of the research process, from planning, recruiting, and data collection to analysis, synthesis, and knowledge management. The through-line? At least in 2025, AI isn’t ready to replace researchers. Instead, we can use it to automate the routine parts of our work (transcribing, tagging, searching, summarizing, routing, statistics, etc.) so researchers can focus on the work and skills that truly matter. While you may be panicking about the future of your job, take one thing to heart: these are all more important in an AI-augmented world and are arguably the hardest things for AI to do well.
When AI handles routine work, the baseline expectation for researchers rises. "We synthesized a study" isn't impressive anymore. AI can do that. What's valuable is understanding which insights actually matter for your organization's specific context, directing your AI assistants to help produce those findings, and building the systems that ensure research shapes decisions.
I’ve spent the better part of this year telling everyone I mentor and coach: Your job isn't simply writing research plans, recruiting participants, or gathering, analyzing, and synthesizing data. Your job is to understand what questions are important to the business and provide answers to those questions.
The researchers who thrive in the future won't be the ones fighting AI or burying their head in the sand, but those who embrace it as a tireless teammate. One who never sleeps, never gets bored of tagging, never forgets to send reminders, and can process 100 transcripts faster than you can read one. That teammate frees you up to do work that's actually important: building trust and rapport with your colleagues, having strategic conversations with leadership, developing deep domain expertise, and ensuring your team builds things that genuinely solve customer problems
AI is a powerful tool, but it requires human judgment to be valuable. It's best at scale, speed, and mechanical work. Humans are best at context, quality, and strategy. The teams that win will be those who thoughtfully combine both.
The future of UX research isn't "AI vs. Human." It's the AI-augmented researcher who can deliver more impact, faster, and more consistently than ever before—not by working harder, but by letting AI handle the parts that don't require human expertise and focusing their energy on the parts that do.
The question isn't whether AI will change research. It already has. The question is: How will you use AI to make your insights impossible to ignore?
Looking forward
While this concludes our five-part series on AI for UX Research in 2025, it’s certainly not the end of the discussion. These tools and technologies will continue to evolve breakneck speed, which means our understanding of how to use them effectively must follow suit. AI (probably) won’t take your job, but someone using AI (probably) will. None of us can see the future, but hopefully this series gives you an idea of how to get started and what to keep an eye out for going forward.
And, as always, I'd love to hear your experiences, your challenges, your ideas, and your questions. Email me or DM me on LinkedIn and let’s co-create the future of AI for UXR together.
Get started
Ready to move beyond storage and start activating your research insights?
- Download the AI x UXR Tool Comparison Guide to see which platforms support knowledge management features.
- Try Great Question's AI-powered repository with automatic tagging, semantic search, and insight synthesis.
- Join the ResearchOps Community to learn from others building insight activation systems.